
Data standards for modern healthcare platforms

The healthcare industry is undergoing a fundamental shift. We are moving away from proprietary silos toward a layered architecture built on global standards such as FHIR, openEHR, and OMOP. The goal is not standardisation for its own sake, but patient data that is liquid, future-proof, and ready for reuse across care delivery, analytics, and research.
At the centre of this shift is the Electronic Health Record (EHR). While the term is widely used, its meaning, and, more importantly, its architectural implications, are often misunderstood. In this article, we focus on what it takes to build an EHR that supports reuse, exchange, and long-term clinical meaning, rather than one that simply digitises existing workflows.
An EHR represents a longitudinal view of a patient’s health journey, aggregating data collected over time and across multiple care settings. Its value lies not in any single dataset, but in its ability to preserve clinical context, support continuity of care, and remain interpretable as systems, standards, and use cases evolve.
So how do we design an EHR that can fulfil that role?
openEHR as the clinical source of truth
To achieve a true 360-degree view of the patient, the first challenge is how clinical information is stored so that it never loses its meaning over time.
This is where openEHR comes in.
Often described as an “instruction manual” for building high-quality clinical records, openEHR is a framework designed around clinical semantics. Its core principle is the use of formal clinical models, known as archetypes, which define how health data should be structured and interpreted. These models allow data to be stored in a way that supports deep interoperability and long-term consistency, independent of any specific application or vendor.
Archetypes act as blueprints for clinical data, embedding context directly into the record through metadata. This ensures that data retains its clinical meaning, even as systems, technologies, and use cases change.
Preserving clinical meaning at the point of capture
To understand the difference between openEHR and standard database in practice, consider how something as simple as a patient’s body weight is recorded. In a traditional database, this might be stored as a single value – for example, 85.2 kg – with little or no surrounding context.
Using an openEHR archetype, the same measurement becomes a complete clinical statement. The record can include whether the patient was standing or sitting, the measurement protocol and equipment used, a precise timestamp, and details such as the level of dress. This additional context is not optional; it is part of the model. As a result, the data remains accurate, comparable, and clinically meaningful over long periods of time.
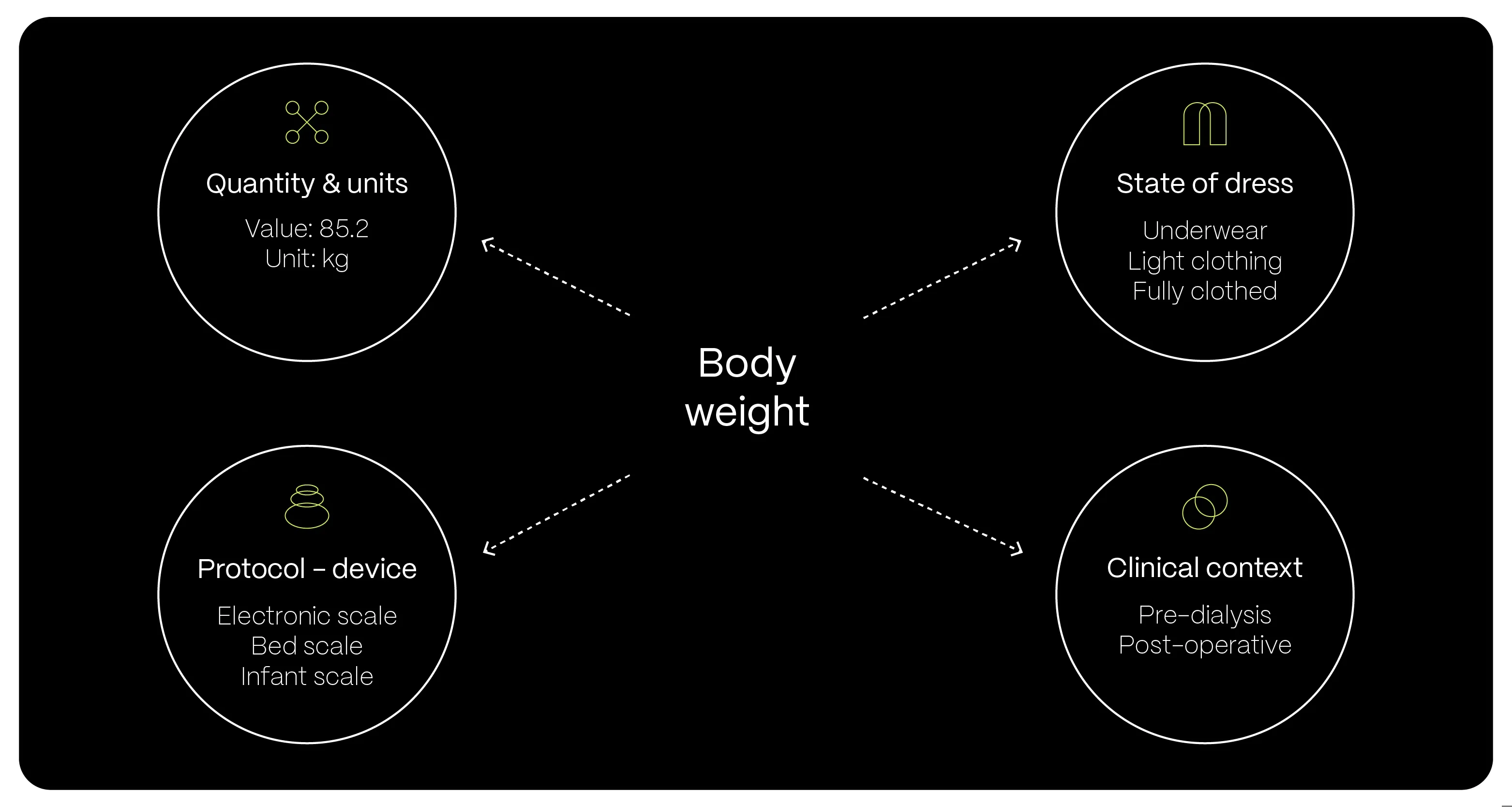
Why is this so important for an EHR?
The core value of an EHR is interoperability.
This model-driven approach enables true vendor neutrality: the clinical data remains usable and interpretable regardless of which software platform is used to store, view, or exchange it.
Effective data organisation starts with a deep understanding of the information we manage. In the openEHR ecosystem, this is achieved through a global community of data experts, software engineers, and most importantly, clinicians. All clinical models/archetypes undergo a rigorous process of review and approval. This ensures that every archetype is not just a piece of code or a definition, but a medically validated 'gold standard.'
Since healthcare is never static, these models are constantly evolving, adapting to new medical discoveries and the shifting needs of the sector. This collaborative approach ensures that the software stays grounded in how medicine is actually practiced, rather than sacrificing clinical accuracy for technical convenience.
For organisations responsible for managing long-term patient records, correctly applying these clinical models is one of the most important architectural decisions they will make. While openEHR may not be a primary tool for every health tech product, it provides a critical foundation for healthcare institutions that operate EHRs and depend on data longevity, consistency, and reuse.
At this point, we can see that openEHR focuses on establishing a rich internal source of truth, preserving clinical context at the point of capture. However, for optimised data exchange, a complementary standard was developed specifically for this purpose.
FHIR as the exchange layer for real-time health data
FHIR is the global industry standard for exchanging healthcare information electronically in real time. Lightweight and built on modern web technologies, it has rapidly become the leading standard for sharing data between disparate healthcare software systems.
A standard designed for precise, real-time exchange
A defining feature of FHIR is its support for granular data access. Instead of exchanging a patient’s entire medical history, systems share specific, well-defined “resources.” These resources are predefined categories (such as Patient, Medication, Observation) that act as a universal language, allowing different apps to request and receive exactly the information they need.
FHIR becomes essential whenever data needs to move between systems or when patients and clinicians require real-time access to health information. It underpins mobile health applications, telemedicine platforms, and wearable devices that need to synchronise continuously with clinical systems.
Being based on modern web APIs makes FHIR a go-to standard for meeting regulatory mandates. Initiatives such as the European Health Data Space (EHDS) and the US 21st Century Cures Act rely on FHIR to ensure patients and authorised third-party applications can access specific data points securely and without delay.
From clinical meaning to interoperable exchange
If we return to the example of a patient’s body weight, the distinction between clinical meaning and exchange becomes clear. While openEHR focuses on preserving the rich clinical “story” behind the data, FHIR focuses on the universal label that allows that data to travel.
In the FHIR model, the same weight measurement is packaged as a Resource – a standardised data object designed for exchange. By using globally recognised codes, such as LOINC, and a consistent structure, FHIR ensures that when a patient’s weight is sent from a hospital system to a mobile application, the receiving system immediately understands what it represents. It is not just a number, but a clinically defined, finalised body weight measurement.
In this sense, FHIR acts as the delivery service for the deep clinical information defined and stored using openEHR. Together, they enable both long-term clinical meaning and real-time interoperability across the healthcare ecosystem.
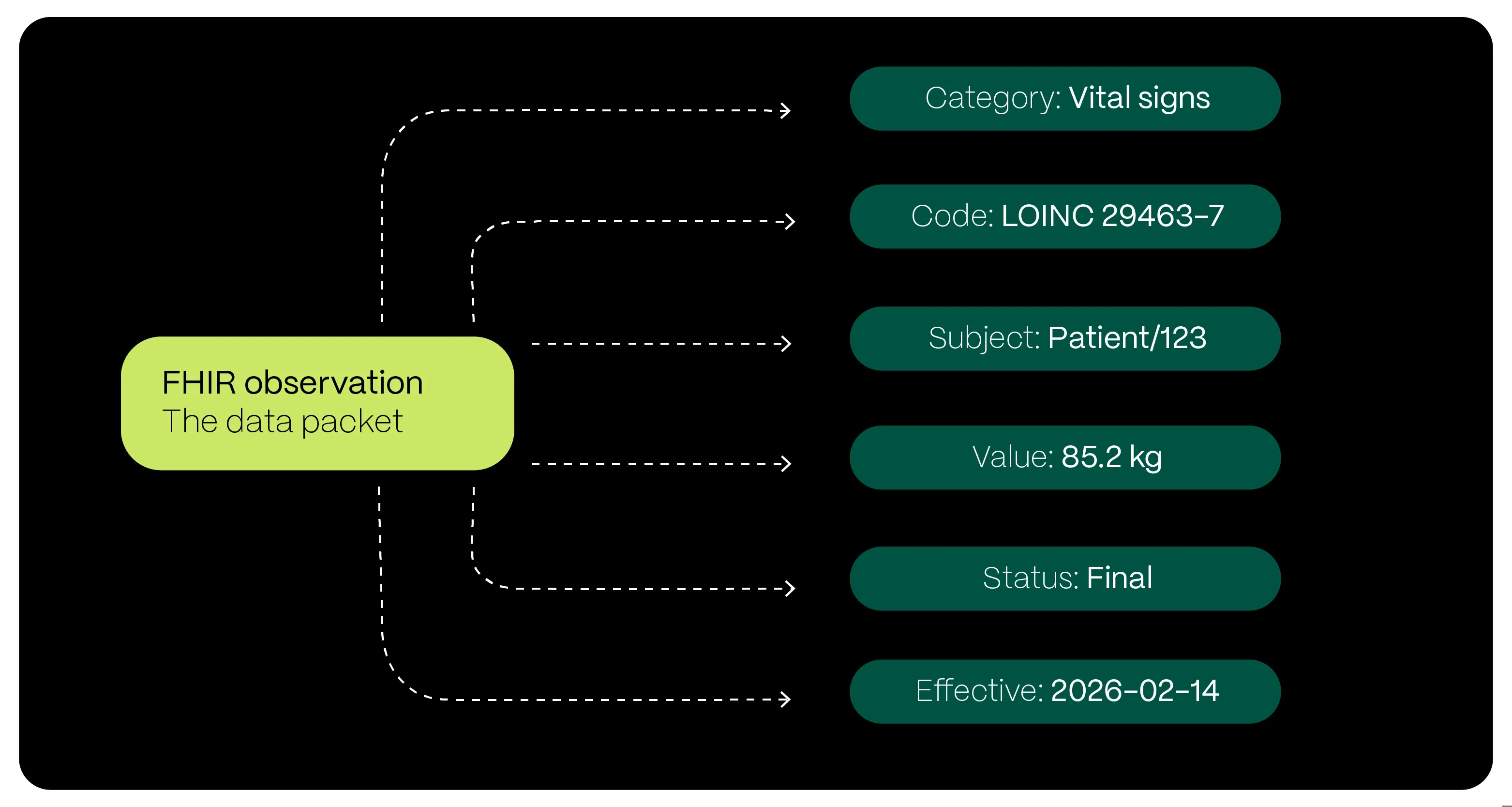
OMOP as the research and analytics layer
To complete the picture, there is one more aspect we need to address to round up the story: OMOP. The natural question is why another standard is needed, and what it provides that openEHR and FHIR do not.
While openEHR and FHIR are essential for clinical care and real-time data exchange, they are not designed for large-scale population research. For “big data” analytics, meta-analyses, and longitudinal studies across millions of patients, healthcare data must be simplified and flattened. This is where OMOP comes into play.
Why clinical and exchange standards are not enough for research
Returning to the example of a patient’s body weight measurement helps illustrate why another standard is needed. To understand this, consider a researcher trying to track drug side effects across a million patients. They might ask: 'Does this specific medication cause a 10% weight gain in children within six months?'
Trying to answer this using openEHR or FHIR alone would be incredibly inefficient. openEHR provides a 'clinical story' that is far too detailed for a computer to scan quickly; as we discussed, an openEHR archetype for weight includes the scale used, the patient's clothing, and even their position. While this is perfect for a doctor treating a single child, a researcher's computer would 'choke' trying to process millions of these detailed stories just to find a single numerical value.
Similarly, FHIR is designed to process one resource at a time, not for moving massive datasets. To answer this question, a researcher would have to make millions of individual requests to a server, one for every weight, every medication, and every diagnosis, which would likely crash the system.
This is where OMOP becomes essential
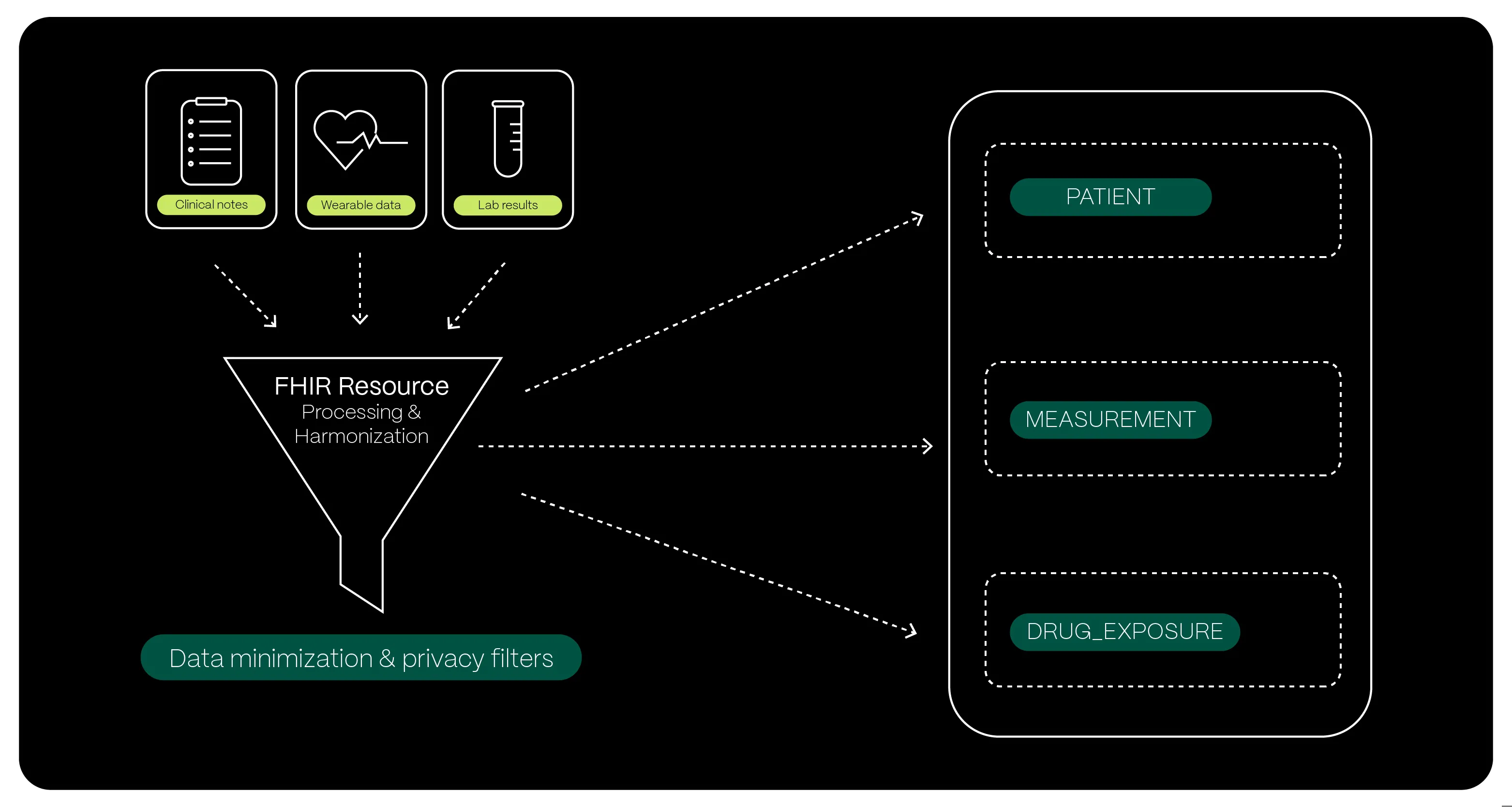
OMOP flattens those complex stories into a standardised, high-speed “research lab” format, allowing scientists to run complex queries across global populations in seconds rather than months.
In the OMOP model, this information lives across three simple tables linked by a unique ID:
- PERSON – identifies the patient anonymously
- DRUG_EXPOSURE – records every instance a patient was prescribed a medication (such as a corticosteroid), noting exactly when the treatment started and ended
- MEASUREMENT – captures the weight values themselves over time
Measurement values are stripped of the complex openEHR “clinical story” and reduced to simple numbers and dates.
Key takeaway
The hallmark of a truly modern digital products and solutions in healthcare is the strategic use of global standards to solve specific clinical and technical challenges. Not every initiative requires the full weight of all three, but having them in our toolkit allows us to scale when complexity demands it.
By aligning our platforms with these shared languages, we ensure that a single body weight measurement can serve a clinician today, a patient-facing application tomorrow, and a life-saving population study years from now. This is how healthcare data moves from isolated records to lasting impact.
