
What Is Stable Diffusion and how does it work?

For the past few years, revolutionary models in the field of AI image generators have appeared. Stable Diffusion is a text-to-image model of Deep Learning published in 2022. It is possible to create images which are conditioned by textual descriptions. In other words the text we write in the prompt will be converted into an image! How is this possible?
Stable Diffusion is a version of the latent diffusion model. Latent spaces are used to get the benefits of the low-dimensional representation of the data. After that, diffusion models and methods of adding and removing the noise are used to generate the image based on the text.
In the following chapters, I will describe latent spaces in more detail as well as the way diffusion models function and I will provide an interesting example of the image which the model can generate based on the given text.
Latent space explained: The foundation behind Stable Diffusion and other diffusion models
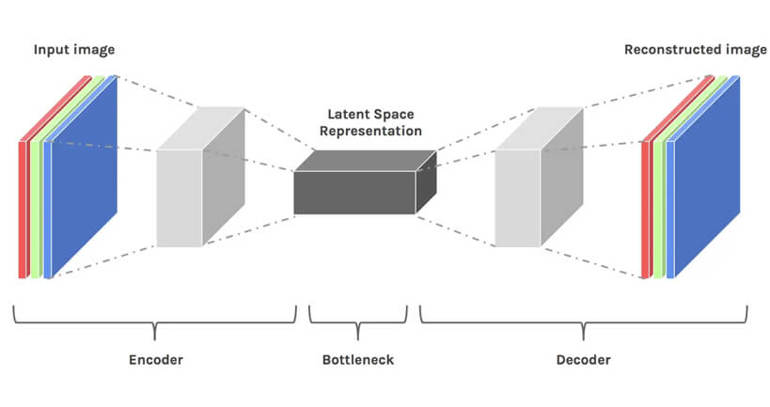
Latent space is, simply put, the representation of compressed data. The compression of data is defined as a process of encoding information by using smaller bits than in the original representation.
Let’s imagine that we have to present a 20-dimensional vector using a 10-dimensional vector. By reducing dimensionality, we are losing data. However, in this case, this is not a bad thing. Reducing dimensionality allows us to filter less important information and keep only the most important information.
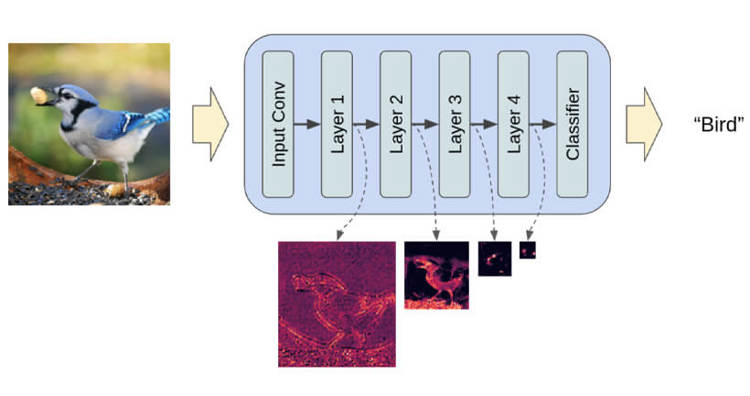
When we want to train the model that classifies images by using fully connected convolutional neural networks, the model is learning specific attributes on each layer of the neural network. These are, for instance, edges, specific angles, shapes, etc. Each time the model has to learn by using data (an already existing image), the dimensions of the image are reduced before they go back to their original size.
In the end, the model reconstructs the image from compressed data by using a decoder, while learning all the relevant information beforehand. Therefore, the space becomes smaller so that the most important attributes are extricated and kept.
This is why the latent space is suitable for diffusion models. It is very useful that there is a way to single out the most important attributes from a training set of a large number of images where there are many details, and that these attributes can be used to classify two arbitrary objects in the same or different categories.
Extricating the most important attributes by using convolutional neural networks (Source: Hackernoon)
Extricating the most important attributes by using convolutional neural networks (Source: Pytorch)
How diffusion models generate images
Diffusion models are generative models. They are used to generate data that are similar to the data on which they have been trained. Fundamentally, diffusion models function in a way they “destroy” trained data by iteratively adding Gaussian noise, and then they learn how to bring back the data by eliminating the noise.

Gaussian noise (Source: Hasty.ai)
Forward diffusion process
Forward diffusion process is the process where more and more noise is added to the picture. Therefore, the image is taken and the noise is added in t different temporal steps, where in the point T, the whole image is just the noise.
Backward diffusion process
Backward diffusion is a reversed process when compared to forward diffusion process where the noise from the temporal step t is iteratively removed in temporal step t-1. This process is repeated until the entire noise has been removed from the image using U-Net convolutional neural network which is, besides all of its applications in machine and deep learning, also trained to estimate the amount of noise on the image.

(Source: NVidia Ddeveloper)
From left to right, the picture demonstrates iterative addition of noise, and from right to left, it showcases iterative removal of the noise.
For estimation and removal of the noise, U-Net is used most often. It is interesting that that neural network has an architecture which reminds us of the letter U, which is how it got its name. U-Net is a fully connected convolutional neural network which makes it very useful for processing on the images.
U-Net is known for its ability to take the image as input and find low-dimensional representation of that image by reducing the sampling, which makes it more suitable for processing and finding the important attributes, and then it reverts the image to the first dimension by increasing the sampling.
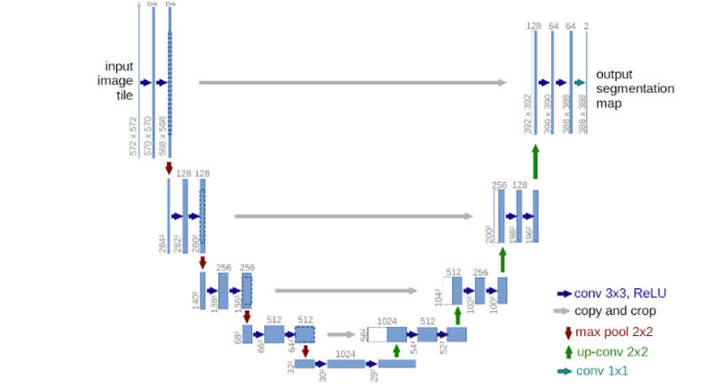
(Source: https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/)
In more detail, removing the noise, i.e. transitioning from arbitrary temporal step t to the temporal step t-1, works as follows. Here, t number is the number between T0 (the original, noise-free image) and TMAX (an image with total noise).
Input is the image in the temporal step t, and in that temporal step there is a specific noise on the image. Using the U-Net neural network, the total amount of noise can be predicted, and then a “part” of the total noise is removed from the image in the temporal step t. This is how you get the image in the temporal step t-1 where there is less noise.
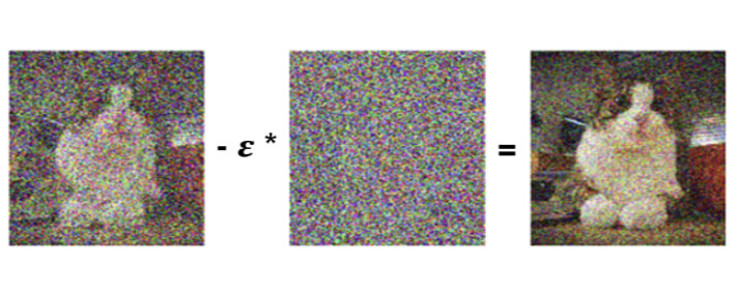
(Source: NVidia Ddeveloper)
Mathematically, there is much more sense to conduct this method T number of times than try to remove the entire noise. By repeating this method, the noise will be gradually removed and we will get a much “cleaner” image.
A simplified process would be: there is an image with the noise and we try to predict the image without the noise by adding complete noise on the initial and removing it iteratively.
(Source: Prog.World)
Text to image Stable Diffusion explained
Inserting the text in this model is done by “embedding” words using language transformers, which means that numbers (tokens) are added to the words, and then this representation of the text is added to the input (to image) in U-Net, it goes through each layer of U-Net neural network and transforms together with the image.
This is done from the first temporal iteration and the same text is added to each following iteration after the first estimation of the noise. We could say that the text “serves as a guideline” for generating the image starting from the first iteration where there is a complete noise and then further down to the entire iterative method.
Why Stable Diffusion is faster and more efficient than other models
The biggest problem of the diffusion models is that they are extremely “expensive” when it comes to time and calculations. Taking into account the way U-Net functions, Stable Diffusion models overcome the above-mentioned problems.
If we wanted to generate the image, with 1024x1024 dimensions, U-Net should use the noise of 1024x1024 size and then make the image out of it. This can be an expensive approach for only one diffusion step, especially if that method would be repeated at times where “t” can be even hundred.
In the following example, the number of temporal steps is 45. The Stable Diffusion model generated two images for the given number of steps in around 6 seconds while some other diffusion models needed even between 5 and 20 minutes depending on GPU specification and the size of the image.
The most interesting part is that a Stable Diffusion model can be set in motion successfully locally with even 8 GB VRAM memory. So far, this problem has been solved by training on a smaller image with the size of 256x256, and then an additional neural network would be used which would produce an image in a bigger resolution (super-resolution diffusion).
The latent diffusion model has a different approach. Concept latent diffusion models do not operate directly on the image but in the latent space! The initial image is actually encoded in much smaller space, so that the noise is added and removed on a low-dimensional representation of our image by using U-Net.
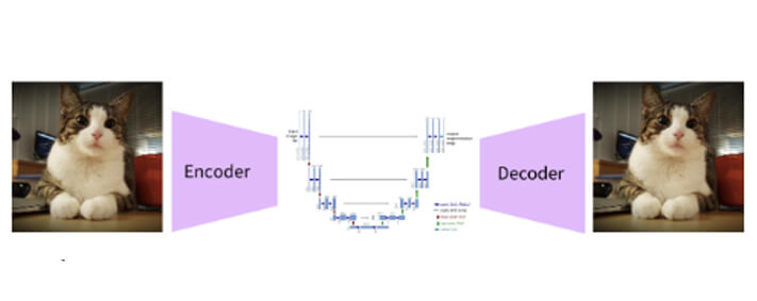
The final architecture of the stable diffusion model
Exploring the creative possibilities of Stable Diffusion
Considering the complex architecture of the mode, Stable Diffusion can generate the image "from scratch" by using a text prompt where it can be described which elements should be shown or left out from the output. Also, it is possible to add new elements on the already existing image also by using the text prompt.
Finally, I’d like to show you one example — on the website huggingface.co, there is a space where you can try different things with Stable Diffusion models. Here are the results when a text “A Pikachu fine dining with a view to the Eiffel Tower" is written in the prompt:

A direct link to the space: https://huggingface.co/spaces/stabilityai/stable-diffusion
Stable Diffusion gained a huge amount of publicity over the last couple of years. The reasons for that are the fact that the source code is available to everybody and that Stable Diffusion does not hold any rights to the generated images. It also allows people to be creative, which can be seen from a large number of incredible published images which this model created. As generative models are developed and improved, we can freely say, on a weekly basis, and it will be very interesting to keep track of their future progress.

Stay in the loop. Subscribe to our newsletter!
Get stories, insights, and ideas that shape the digital world, straight from our team.
Sign up hereStable Diffusion in 2026
By 2026, Stable Diffusion has evolved from a breakthrough image generation model into a broader ecosystem used to build and control generative workflows. While newer closed models often deliver stronger out-of-the-box image quality, Stable Diffusion remains highly relevant due to its flexibility, open nature, and ability to run locally on consumer hardware.
Its strength now lies in control and customisation. Through tools such as ControlNet, LoRA fine-tuning, and node-based interfaces like ComfyUI, users can guide composition, structure, and style through different forms of conditioning and fine-tuning. This makes Stable Diffusion particularly valuable for developers, researchers, and teams building tailored generative solutions.
Rather than being used only as a standalone model, Stable Diffusion is increasingly integrated into end-to-end creative and production pipelines, supporting tasks such as image generation, editing, and iterative design. As a result, it is best understood not just as a model, but as a flexible foundation for experimentation, customisation, and production use.
