
Intent classification: understanding text with the power of AI
In today’s world, with the expansion of data generated from various sources, analyzing it has become a critical challenge for businesses.

Textual data makes up a significant percentage of this vast data volume. Therefore, understanding and extracting meaning from it is more important and useful than ever. Customer reviews, social media posts, and emails are just some examples of common textual data which contains information that can provide valuable insights and help businesses identify opportunities for improving performance along with their customers’ experience.
One of the key aspects of analyzing textual data, among many Natural Language Processing (NLP) techniques, is intent classification, which involves identifying the underlying purpose behind a piece of text. In other words, it is used for understanding user input which then leads to giving the most adequate answer to the user.
What is an intent and how is it defined?
The purpose behind user input that is being analyzed is called intent.
Intents can be predefined, in which case we find a way to classify user input into one of the previously defined intents. The input “I would like to order the article no. X” could be mapped to an intent “Make an order”. Predefined intents are used in applications whose domain is limited.
For example, a virtual assistant for specific predefined tasks such as providing weather-related information, translating text, navigation assisting, etc. In this case, the Machine Learning (ML) algorithm is trained on a dataset that contains previously defined intents, without the possibility of automatically generating new ones.
Intents can also be dynamic which means that they are learned from the previous user interactions. Dynamic intents are used in applications where the domain is not strictly defined, but changeable. In the example of a virtual assistant, dynamic intents would be used in assistants for some general tasks that are not defined in advance where the assistant is expected to provide general information about any topic, perform web searches to retrieve information, make recommendations, etc.
How does intent classification work?
There are two main approaches when working with intent classification:
-
Rule-based approach
There are defined rules by which user input is classified into one of the intents. Rules can imply that the input must contain specific keywords or phrases in order to be classified as a specific intent.
-
Machine learning approach
Different models can be trained on data containing examples of user input and the corresponding intent, such as logistic regression, random forest, CNN, and RNN.
The combination of these two approaches is possible as well when needed. Considering the topic of this blog, we will focus on the machine learning approach.
Preparing the dataset
The dataset needed for the ML model training should contain examples of user inputs and intents that correspond to them. Based on these examples, the model learns how to classify an incoming input into one of the intent categories. Whichever ML algorithm is used, the model data should be preprocessed before the training.
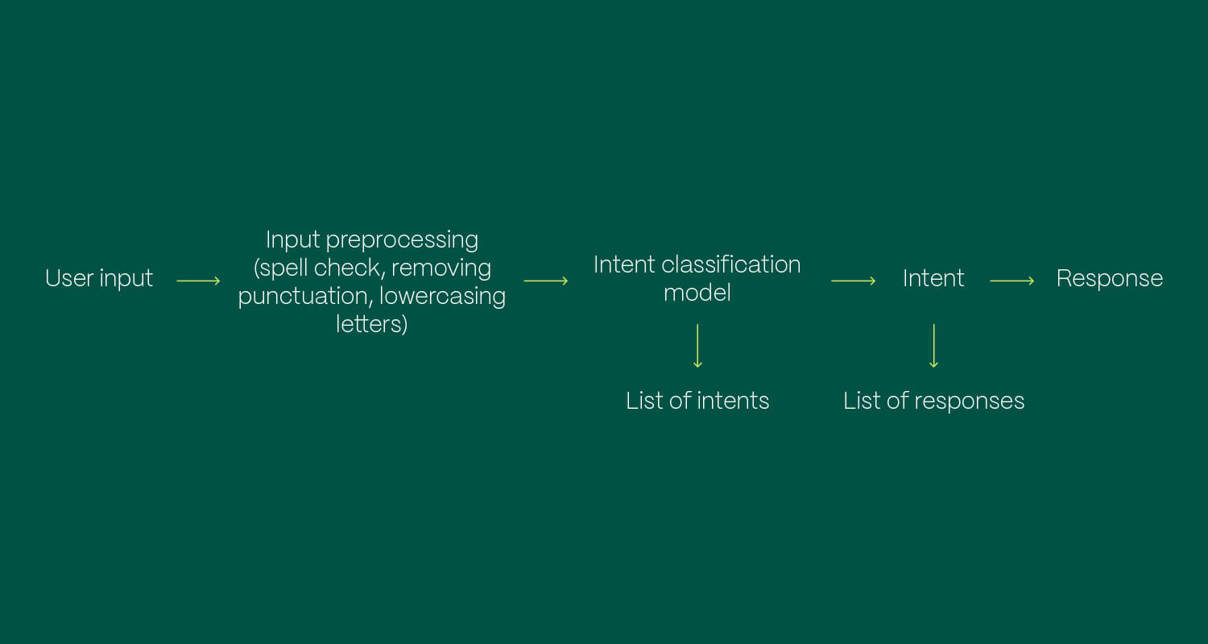
Data preprocessing implies cleaning the data - lowercasing letters, removing punctuation and contractions, performing spell check, etc. The main goal of data cleaning is to eliminate the impact of lexical variation in user input on its classification. Furthermore, the dataset should be balanced, which means that each intent in the dataset should have approximately the same number of user input examples. A balanced dataset is needed since if the model is trained on significantly more examples of one intent compared to the others, that intent will have a higher probability when classifying user input.
Training the model
After data preprocessing, the dataset is split into two datasets - train and test. The model is trained on the training dataset, which contains around 70-90% of the whole dataset (depending on the size of the dataset and the data quality). It learns from the examples of user input, finds patterns by which it will be able to classify any user input that comes in the future into one of the intents.
After the model is trained, for a specific input and each of the intents, it provides the probability that the input is classified into that particular intent. The intent with the highest probability is typically considered the predicted intent for that user input.
The model is being evaluated using the test dataset. Model evaluation is done by comparing the predicted intent to the expected one for a particular user input. There are different evaluation metrics, but all of them share the same idea of identifying the number of correctly classified examples.
Defining “Unknown” intent
Real-world user inputs may contain words, phrases, or patterns that were not present in the training data. In such cases, the model may struggle to accurately classify the input into any of the predefined intents. By including the "Unknown" intent, the model can have a fallback option to capture and handle such inputs.
Examples of “Unknown” intent for the model training could also be some random user statements or questions, which are not related to the domain for which the model is being trained. In some intent classification models, if there is no “Unknown” intent, this type of input would be classified into one of the predefined intents and would get the corresponding answer. Using “Unknown” intent, this kind of input can get an answer that the message is not understandable and the user would be asked to reformulate it.
What happens after getting the intent?
After predicting the intent of user input, most often there is a need to provide an answer to the user.
Answers that are returned to users can be predefined or generative. In the former case, a list of all the possible answers exists, where each intent is related to a specific answer, and after classifying user input into one of the intents, the corresponding answer is returned to the user. In the latter case, the list of predefined answers does not exist. Instead, machine learning is used to generate answers by training models on large datasets of textual data.
These models learn patterns from the data and can then generate responses based on those patterns. Generative models are a subject on their own and require dedicated attention due to their complexity.

Intent classification applications
Intent classification has a wide range of applications in various fields. We will focus on three of them. There are some other areas where it can be applied, including customer service and fraud detection.
Chatbots
Chatbots use intent classification for identifying the user's intention behind the input, such as asking for information or making a request, after which they provide an answer. As stated before, answers can be predefined or generated, depending on the way the chatbot is created.
The input could be in the form of text, voice, or some other format depending on the chatbot's capabilities. If the input is in the form of voice, there is a need to first convert voice to text, that could be done using various Speech to text AI services. In chatbots, the “Unknown” intent could be of great importance, in a way that for unknown inputs chatbot could ask a user to rephrase his message.
Email filtering
Intent classification is also used for email filtering. Categorizing incoming emails into different predefined categories: “important”, “social”, “promotions”, “newsletters”, etc. This can help users organize their inboxes, prioritize important emails, and quickly locate specific types of emails. Intent classification can also be used for identifying spam emails, by training the model that can learn to recognize common patterns and characteristics of spam emails.
SEO
Intent classification is an important concept in search engine optimization (SEO) as well, as it helps businesses better understand the motivation behind user search queries. For example, a user query that aims to get information about a specific topic could be classified as informational intent while a query of a user who intends to do research on products in order to eventually buy one of them could be classified as a commercial intent. By classifying user queries, SEO professionals can create more effective strategies to target and convert potential customers.

Intent classification leads to better customer experiences
We have gained insight into the importance of intent classification in solving a variety of problems that include interactions with users. As the field of NLP and AI, in general, continue to improve, we can expect further advancements in intent classification techniques, which will be able to help us solve a greater spectrum of problems in everyday life.
