
Understanding dependency and control inversion

There are a few of concepts that are highly related and very important for the design of modern applications:
- Dependency Injection pattern
- Dependency Inversion principle
- Inversion of Control principle
All of them overlap in some areas, they seem similar but if you focus on problems they try to solve you see that there are clear differences between them. The purpose of this blog is to clear up what distinguishes them and to gradually show why have we introduced those concepts into the modern applications design.
If you remember, a while ago when we started developing, our code wasn’t that great. Back then this was probably something hard to admit. Even though quite functional and usable, it wasn’t quite user-friendly to new requirements, maintenance, nor was it reusable. Our primary goal was simply to compose architecture which delivers desired functionality in any possible way. Some of the mistakes we often made were: creating business classes inside of others – so to hide dependencies, using singletons and service locators everywhere but also static classes and variables, and the list goes on. All those decisions lead to a design which is not flexible, that is hard to maintain, reuse or test.
Now, let’s go into one example which utilizes singleton (old fashion design), and see how it evolves to a better one. If we have a class Person:
public class Person{ public string Name { get; set; } public string SurName { get; set; } public int Age { get; set; }}
And DataProvider class, which works with SQL data source:
public class DataProvider{ private static DataProvider _instance = new DataProvider(); private DataProvider() { } public static DataProvider Instance { get { return _instance; } } public void AddPerson(Person person) { //SQL logic for inserting a new person… } public IEnumerable<Person> GetAll() { //SQL logic for obtaining all persons… } public void Clean() { //SQL logic for clearing all entries… }}
And if the following business class DataImporter, with the purpose of taking data from a source and importing it to an appropriate file, looks like:
public class DataImporter{ private string _destinationFilePath; public DataImporter(string destinationFilePath) { _destinationFilePath = destinationFilePath; } public void Import() { using (StreamWriter sw = new StreamWriter(_destinationFilePath, true)) { foreach (var person in DataProvider.Instance.GetAll()) { sw.WriteLine(person.ToString()); } } }}
..We made a block which is functional, but it has a hidden problem or defect, if we can express it that way. DataImporter has completely hidden the fact that it uses DataImporter class instance. You are not aware of it if you simply look at the API of it:
public class DataImporter{ public DataImporter(string destinationFilePath); public void Import();}
As you can see, there is no mention of DataProvider. If you want to cover this class by unit tests, everything becomes much harder because you have the singleton DataProvider, and singleton pattern doesn’t fit well together with unit testing!
The natural way to fix this kind of problem is to inject dependency into Dataimporter. And with this we get to the first important concept of the topic: Dependency Injection Pattern.
What is Dependency Injection Pattern?
Dependency Injection pattern is a software design pattern which provides solution to create loosely coupled components. Injecting dependencies to a component instead of allowing it to find dependencies by itself (by servicelocator, singleton, or any other way) is the essence of this pattern.
This can be done in a couple of ways:
- Parameter injection, providing dependency through method parameter,
- Property injection, through a class property,
- Constructor injection, through a class constructor.
Property injection is the least explicit way to emphasize that your class requires some dependency, it’s mostly used to indicate that dependency is optional, therefore not entirely required by your class instance to work. Parameter injection indicates that some method of your class requires additional dependency, but mostly this dependency is not required by the entire class. Constructor injection is the most explicit way to say that your class instance requires dependency on another class. In most cases, you will end up with this type of injection.
Before we change our code, let’s just briefly define what Dependency Injection pattern includes:
- Injecting dependencies instead of locating them (by service locator, singleton, etc.),
- Interfaces, abstractions by which we will communicate with dependencies, we will describe this later on as we introduce new requirements in the example.
- The injector, a piece of code responsible for constructing dependencies and passing them where needed. Mostly this part of a code is known as a composition root, and it’s very close to the application start.
Now, if we want to inject DataProvider instance into DataImporter, our DataImporter class definition will look like:
public class DataImporter{ private string _destinationFilePath; private DataProvider _dataProvider; public DataImporter(string destinationFilePath, DataProvider dataProvider) { _destinationFilePath = destinationFilePath; _dataProvider = dataProvider; } public void Import() { using (StreamWriter sw = new StreamWriter(_destinationFilePath, true)) { foreach (var person in _dataProvider.GetAll()) { sw.WriteLine(person.ToString()); } } }}
This design clearly indicates that DataImporter requires DataProvider, as we can see from API too:
public class DataImporter{ public DataImporter(string destinationFilePath, DataProvider dataProvider); public void Import();}
So, no hidden dependencies, it’s clear what we need in order to run DataImporter or to test it. This is a small change, but a big improvement in our design.
Here I would just like to emphasize one thing: Passing any kind of dependency can cause problems and reduce readability and maintainability. We always have to think what we have coupled by some dependency, and does it make sense. For example, if we have two classes - DataReader which reads some limited string from a server and DataFiltrer class which cleans string according to some policy (removes invalid chars, etc), it might seem reasonable to a developer to couple those two classes like at the image bellow:

But, we are making those two classes highly coupled without any good reason, because instance of class DataFilter requires ONLY string as dependency, a content itself, not the entire DataReader instance. Also, changing DataReader will affect DataFilter class even though it doesn’t make sense for it to happen! Instead the proper design would look like:

This kind of problem, and the rule built to prevent it, is described in the principle called “Law of Demeter” or principle of least knowledge. Since that is not the main focus of this reading, I won’t go into details of it, but I would highly recommend to introduce yourself to this principle.
Now let’s go back to our main example and extend our requirements. Imagine that we have a requirement to cover our classes by unit tests and reuse DataImporter instance elsewhere but we need to import data from XML data source instead of the SQL. So, we need DataProvider instance which works with XML. This is a problem for the current design, because we have a strong dependency to DataProvider which works explicitly with SQL data source. Wouldn’t it be nice if DataImporter could work with any kind of data source?? Also, if we would have this capability we would easily make unit tests for DataImporter by providing dummy implementation of DataProvider. With this requirement we arrive to the second important concept: Dependency Inversion Principle.
What is Dependency Inversion Principle?
According to Dependency Inversion Principle, the implementation details should depend on high level abstractions and not the other way around. Also, modules on higher level shouldn’t depend on modules on lower level, they should both depend on abstractions.
So, in our example and in order to fulfil new requirements, we need a way to provide the abstraction. There are a couple of constructions present in modern languages used to introduce abstraction, but the mostly common used one is the Interface.
Interface is the basic tool for dividing abstraction from concrete implementation. It’s a pattern by itself and it lays in the very heart of almost all commonly used design patterns!
The Interface, which suits our case, will have the following form:
public interface IDataProvider{ void AddPerson(Person person); IEnumerable<Person> GetAll(); void Clean();}
If we have interface in place, our DataImporter class definition will look like:
public class DataImporter{ private string _destinationFilePath; private IDataProvider _dataProvider; public DataImporter(string destinationFilePath, IDataProvider dataProvider) { _destinationFilePath = destinationFilePath; _dataProvider = dataProvider; } public void Import() { using (StreamWriter sw = new StreamWriter(_destinationFilePath, true)) { foreach (var person in _dataProvider.GetAll()) { sw.WriteLine(person.ToString()); } } }}
Now we can easily create the XML version of DataProvider and pass it to DataImporter, which doesn’t care anymore which concrete data source is used. Bear in mind that there is no more need to use singleton in the design. For the unit test purpose we can create a simple implementation of IDataProvider which looks like:
public class InMemoryDataProvider{ private List<Person> _persons = new List<Person>(); public void AddPerson(Person person) { _persons.Add(person); } public IEnumerable<Person> GetAll() { return _persons; } public void Clean() { _persons.Clear(); }}
Here, and by introducing abstraction IDataProvider, we made our DataImporter class flexible, reusable - independent of actual data source, and easy to test! So, on class level, we have successfully decoupled it from a concrete DataProvider and instead we rely only on abstraction (first part of Dependency Inversion).
The question that still remains is: Can we apply a similar inversion on a higher level of software architecture, package or layer level?! The answer is YES. That is exactly what the second part of Dependency Inversion definition refers to. If we leave interface in the same package where we have interface implementations, then we still have traditional dependencies coming from top to bottom. Our modules on a higher level still depend on modules on a lower level. Take a look at the following image.
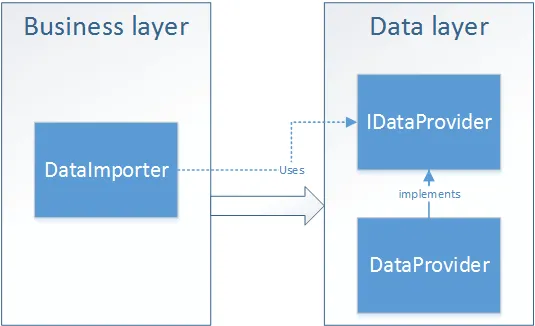
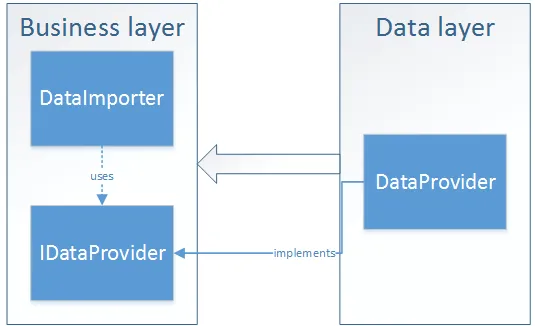
But, if we move interface to the level above, our dependencies will be reversed! In this case, we can make as many changes as we want in the implementation of data layer itself and it won’t affect the layer above.
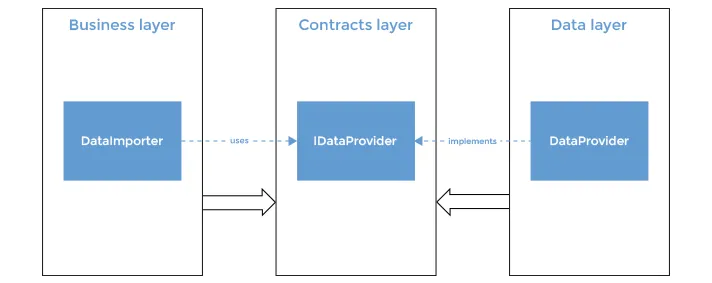
There is one more approach for storing interfaces since, for most developers, having interfaces stored in the package where interface consumer module is located would seem unnatural... We can store interfaces separately, by grouping them in Contracts layer. In that case business layer modules would depend only of Contracts and they will be decoupled from concrete data layer, which is our final goal.
So as you can see, Dependency Inversion Principle helps us develop a structure which is flexible - easy to change, test and reuse. If correctly followed, the principle can ensure that you can easily reuse or change a class or component, but also bigger modules or even layers.
In order to explain Inversion of Control principle, we have to move to a different kind of problem. Before, with a traditional approach to building applications, we created high level modules which had some reusable libraries and modules in them, therefore having modules on a lower level. Any extension of the application required complete rebuilding. Also, the modules on a higher level since dependent on low level modules, needed to know about the infrastructure details of the application. And this was quite tedious and prone to error. We wanted to extend our applications easily in runtime, without any need to recompile and also, while writing new high level modules, we didn’t want to be bothered too much with infrastructure details. And that’s exactly where Inversion of Control principle comes in.
What is Inversion of Control Principle?
Inversion of Control Principle is a design principle where custom modules or blocks on higher level, describing application identity and behavior, receive the flow of control from a generic framework.
So, instead of calling lower level modules in order to accomplish some task, a custom written code on a higher level is called by a generic framework. The framework hides most of the infrastructure details and provides only necessary context to custom modules. As you can see, Inversion of Control principle affects the structure of our design (like DI principle) but it also affects and inverts communication (flow of control) between modules. It increases modularity of application and makes it really extensible.
The generic framework defines all required interfaces for different types of components, that will communicate with it and that will come as custom portions of code on a higher level. For example, if we have a development environment such as Visual Studio, we want to have specific interfaces for custom panels, custom actions, menu items, custom background processes and etc. Look at the following picture which illustrates modern applications with generic framework and custom building blocks.
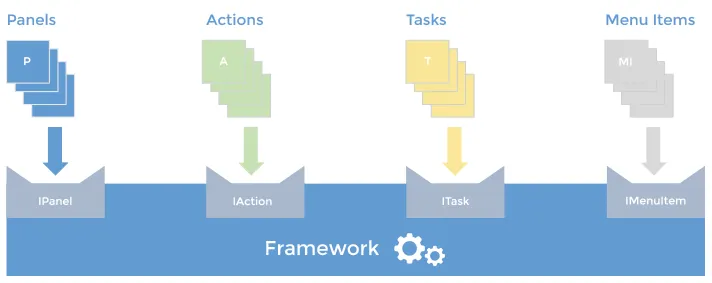
By providing specific context for each custom component, the one which contains only data and functions relevant for communication with the framework and vice versa, we are minimizing the possibility of a component doing something undesirable. Also, we minimize the effort of writing custom components, since a developer needs to be familiar only with component context, not with the entire system.
Having said all of this we can now define the design purposes of IOC principle:
- To decouple task execution from its implementation. Inner details of task execution are moved into the framework.
- To focus a custom written module to task itself. We are getting corresponding task context and we don’t have to care about execution since framework does this.
- To free modules from assumption about how other systems do what they do and instead rely on contracts.
- To prevent or minimize side effects when modules are replaced or introduced.
Conclusion
As you can see there is a clear difference between Dependency Inversion, Inversion of Control and Dependency Injection pattern. Just focus on the problems they try to solve and it’s easier to distinguish them. Today it’s almost unthinkable to write a decent code without them, therefore make sure to follow the mentioned rules in order to make your code easy to change, extend, test or reuse.
