
C# 8 – The Shape of the Things to Come

Did you know that C# has been around for 17 years? It started off as Microsoft’s response to Java, but now, in its “late-teen” years and seven revisions later, it is one powerful and popular language. Recently, C# has introduced more innovations in a short period of time than ever before. In general, all Microsoft technologies have an accelerated rate of innovations.
This is due to the fact that Microsoft has made a few new decisions that affected all its developer products and technologies. The first of them was to decouple releases of Visual Studio, .NET framework, and C#, giving them space to breathe and follow their own paths. Before, these technologies were shipped together, and that kind of slowed down the progress of each of them. This also affected the pace of releases, which has increased in the past few years.

The second change that Microsoft has introduced is that it is much more open to developers than it was in the previous period. By this, I mean that we can now follow Microsoft’s GitHub, and learn about new features, even though these features are only in the proposals state. That is how we can see some of the proposed features that will be available in new version of C#.
Don’t get me wrong, C# 8 is not scheduled anytime soon. After all, there is already work ongoing towards C# 7.2 and it looks like there are also plans for a C# 7.3. So, this revision is far down the road. Still, we can take a peek at some of the new shiny things that will be provided. Some of the features were already presented by Mads Torgersen in an interview on channel 9 and I am pretty excited about some of them. So, let’s check some of them out.
Nullable Reference Types
I think I read somewhere that 70% of all bugs in C# are directly correlated to the null reference exception, but don’t take my word for it, because at this moment I cannot find the reference or source of this statement. Still, I would not be surprised if that were true. Even the creator of null concept (first introduced in Algol W language in 1965), Tony Hoare, called it ‘billion-dollar mistake’ and publicly apologized for it. Still, it seems that now we are stuck with this concept and all its pitfalls.
C# has a history with null, too. Language has two large types of variables, primitive and reference, and only reference variables can have the null value. In fact, reference types have the null value as default. But, in C# 2.0 Microsoft introduced nullable versions of primitive types, which are denoted by a ‘?’ after type name. This means that ‘int?’ is basically an integer variable that can have the null value. As you can imagine, this allowed the null reference exception to hide in various sections of the code.
Thus far, the community used partial solutions like Code Contracts or third-party solutions, like Fody NullGuard, to forbid assignment of the null value to some variables, but language support for this problem is long overdue. It seems that C# 8 will change this by introducing the Null Reference Type. This feature will give developers options to define references which are non-nullable.
Per the design proposal, you would still be able to do something like this:

Now, this code will generate a warning because String cannot have value null. Instead, this code should be used:

However, this will probably cause Write function to generate a warning because it should not accept nullable values. This cascade of warnings will help us detect stuff we are not doing in a properly.
Of course, this feature will be opt-in, so the legacy code will not produce a bunch of these warnings. I must say that I like this very much. This way we will be able to avoid Null Reference Exceptions in runtime.
Records
Ok, I am very excited about this for multiple reasons. For instance, I still can remember when I was just starting to code, and I was so confused with the way the operator ‘==’ works on primitives and the way it works on reference types. Take a look at this:
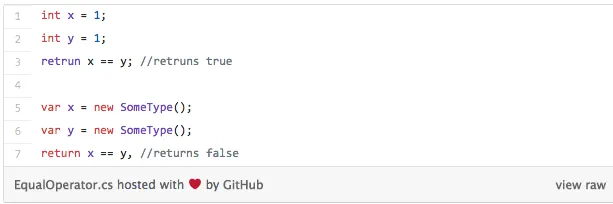
So, this operator works in a way that is sort of expected for primitives, which is not the case for reference types. Of course, this is because C# compares reference types for referential equality, but we can all agree that this is really intuitive and it can be confusing. Enter the stage Record type, the idea that already exists in F#.
This type is basically just a collection of fields. All you will have to do is define it like so:

The first benefit that we will have from this feature is that ‘==’ operator will now check the structural equality, and it will be more intuitive and natural, especially for newcomers to C#. The second (and huge) benefit is that this will save us from writing a bunch of boring, boilerplate code. The compiler will do all tedious work for us, and based on the upper definition of Record, it will generate something like this:

Yes, that is a lot of code you don’t have to write anymore. This is not a ground-breaking alteration of the language, but it is still an awesome one. Check out the proposal for more information.
Async Streams and Async Dispose
As we can remember C# 5.0 was all about asynchronous programming. Nevertheless, a few C# features were left out from these innovations. One of those are asynchronous enumerations. By this, I mean that you cannot iterate through some collection in an asynchronous manner – all you can do is get all the elements this way. This leaves you with the fact that asynchronous use of LINQ is also impossible (or at least not done easily). The guys from C# team decided to change this. Basically, you should be able to do something that will look like this now:
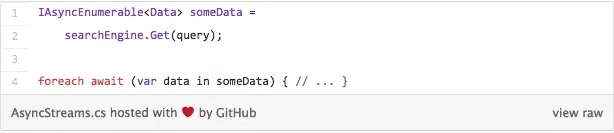
As you can see, the idea is to have the IAsyncEnumerable which will return element by element asynchronously. Of course, this leaves a bunch of open questions as to how cancellation will be handled, and how this will affect code complexity. Apart from that, for this feature to be complete, full LINQ support will have to be done.
Another feature that was not enriched with asynchronous functionality is Dispose. We are still doing Dispose synchronously these days, except we don’t make a workaround that looks something like this:

Naturally, this hack that we would place in our finally block is not something we want to do. So, idea is that something like this can be done:
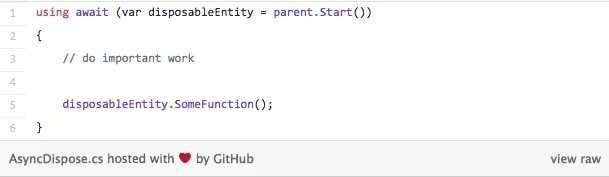
In order to achieve this, C# will introduce a new interface IAsyncDisposable. To get more information on these features, check out the proposal here.
Default Interface Implementations
Did you just make your most skeptical face while reading this the paragraph title? I know that I did when I first read it. The question that popped instantly into my head was ‘Why would you put any concrete implementation in the interface when you have an abstract class for that?’. Still, allow me to explain what the idea behind this concept is.
Have you ever found yourself in a situation where you have to extend some interface with some functionality? I definitely have. And, the problem that occurred then is that all classes that were implementing that interface had to implement this new method. In that moment, I would ask myself ‘Do I follow Interface Segregation Principle?’. But, if you work on extensions for legacy systems, and you know you need backward compatibility, this feature will make your life much easier.
In a nutshell, you will be able to do this:
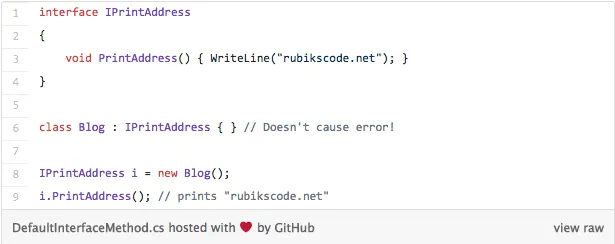
From what I understand, these implemented methods would become virtual methods of the interface, which implementation can override or not. This is one interesting feature, that will further reduce the difference between interfaces and abstract classes. To get more information on these features, check out the proposal here.
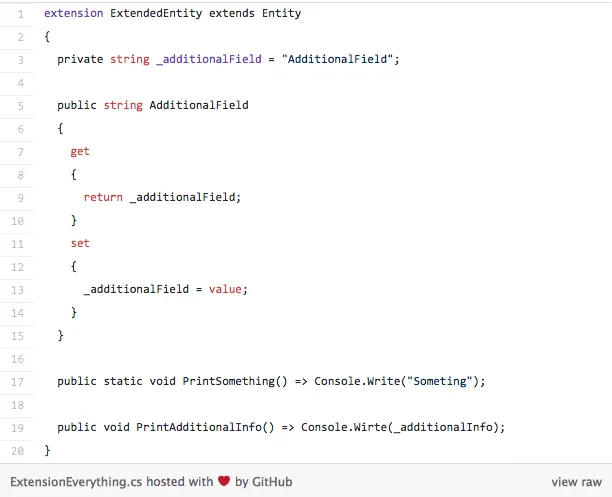
Extension Everything
This is the feature that I think is cool, but I am kind of afraid of its consequences. Nevertheless, it feels like a natural progression of the language itself. The idea is to apply the concept of extension methods from C# 3 to properties, fields, static fields and static methods. This way you will be able to add anything to a type.

Effectively, this means that you will be able to add a whole new functionality to a type, without touching the original code. In addition to that, the original code will not be able to interfere with this new functionality. That is great from the point of separation concerns. What I am having mixed feelings about is the way that this will affect the code itself. Even now, with just extension methods, the code can be somewhat complicated to understand. Still, perhaps I am mistaken and this new feature will actually clean that code up as it will contain the entire functionality.
The syntax will look like something like this:
Conclusion
Even though we will not see C# 8 anytime soon, I am super excited about some of the features that it could bring. Also, since these are just glimpses of features that could be introduced, I am curious about how these functionalities will be integrated under the hood. What do you think? Would these features help you in writing more elegant solutions?
